Required SageMaker Python SDK parameters¶
The TensorFlow and PyTorch Estimator objects contains a distribution parameter,
which is used to enable and specify parameters for the
initialization of the SageMaker distributed model parallel library. The library internally uses MPI,
so in order to use model parallelism, MPI must also be enabled using the distribution parameter.
The following is an example of how you can launch a new PyTorch training job with the library.
sagemaker_session = sagemaker.session.Session(boto_session=session)
mpi_options = {
"enabled" : True,
"processes_per_host" : 8,
"custom_mpi_options" : "--mca btl_vader_single_copy_mechanism none "
}
smp_options = {
"enabled":True,
"parameters": {
"microbatches": 4,
"placement_strategy": "spread",
"pipeline": "interleaved",
"optimize": "speed",
"partitions": 2,
"ddp": True,
}
}
smd_mp_estimator = PyTorch(
entry_point="training-script.py", # Pick your train script
source_dir='utils',
role=role,
instance_type='ml.p3.16xlarge',
sagemaker_session=sagemaker_session,
framework_version='1.6.0',
py_version='py3',
instance_count=1,
distribution={
"smdistributed": {"modelparallel": smp_options},
"mpi": mpi_options
},
base_job_name="SMD-MP-demo",
)
smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
smdistributed Parameters¶
You can use the following parameters to initialize the library using the parameters
in the smdistributed of distribution.
Note: partitions is required in parameters of smp_options. All other parameters in the following
table are optional.
Parameter |
Type / Valid values |
Default |
Description |
|
int |
The number of partitions to split the model into. |
|
|
int |
1 |
The number of microbatches to perform pipelining over. 1 means no pipelining. Batch size must be divisible by the number of microbatches. |
|
|
|
The pipeline schedule. |
|
|
|
Whether the library should optimize for speed or memory during partitioning decision and pipeline execution. speed When the library is configured to optimize speed, it attempts to balance the number of operations executed in each device, and executes a less strict pipeline schedule in which a microbatch can start executing before the previous microbatch is completely finished on that device. memory When the library optimizes memory, it attempts to balance the total number of stored trainable parameters and activations on each device and imposes a strict pipeline schedule on the backend. |
|
|
|
When hybrid model/data parallelism is used, cluster places a single model replica in neighboring device IDs, whereas spread places them as far as possible. Example: - 8 GPUs: [0, 1, 2, 3, 4, 5, 6, 7], 4-way model parallelism, 2-way data parallelism. Two model replicas, each partitioned across 4 GPUs. spread places the two model replicas in [0, 2, 4, 6] and [1, 3, 5, 7]. cluster places the two model replicas in [0, 1, 2, 3] and [4, 5, 6, 7]. This can be useful, for instance, for performing model parallelism across instances, and leaving the intra-node high-bandwidth NVLinks for data parallelism. |
|
bool |
|
Enable
auto-partitioning.
If disabled,
|
(required if auto_partition if false) |
int |
|
The partition
ID to place
operations/modules
that are not
placed in any
|
TensorFlow-specific parameters
Parameter |
Type / Valid values |
Default |
Description |
|
bool |
|
Whether the model partitions should be contiguous. If true, each partition forms a connected component in the computational graph, unless the graph itself is not connected. |
|
bool |
|
Must be set to
|
PyTorch-specific parameters
Parameter |
Type / Valid values |
Default |
Description |
|
float (between 0.0 and 1.0) |
0.2 if
|
The weight of memory balancing in the auto-partitioni ng objective, as opposed to balancing computational load. If 0.0, the library only tries to balance computation; if 1.0 the library only tries to balance the memory use. Any value in between interpolates between these extremes. |
|
bool |
|
Must be set to
|
|
int |
|
This is the maximum number of microbatches that are simultaneously in execution during pipelining. Jointly scaling batch size and number of microbatches can often mitigate the pipeline bubble overhead, but that can lead to increased memory usage if too many microbatches are simultaneously in execution. In such cases setting the number of active microbatches to a lower number can help control memory usage. By default this is set to two plus the number of partitions of the model. |
|
bool |
|
Setting this to true ensures that the execution server for pipelining executes requests in the same order across all data parallel ranks. |
mpi Parameters¶
For the "mpi" key, a dict must be passed which contains:
"enabled": Set toTrueto launch the training job with MPI."processes_per_host": Specifies the number of processes MPI should launch on each host. In SageMaker a host is a single Amazon EC2 ml instance. The SageMaker distributed model parallel library maintains a one-to-one mapping between processes and GPUs across model and data parallelism. This means that SageMaker schedules each process on a single, separate GPU and no GPU contains more than one process. If you are using PyTorch, you must restrict each process to its own device usingtorch.cuda.set_device(smp.local_rank()). To learn more, see Modify a PyTorch Training Script.Important
process_per_hostmust be less than or equal to the number of GPUs per instance, and typically will be equal to the number of GPUs per instance.For example, if you use one instance with 4-way model parallelism and 2-way data parallelism, then processes_per_host should be 2 x 4 = 8. Therefore, you must choose an instance that has at least 8 GPUs, such as an ml.p3.16xlarge.
The following image illustrates how 2-way data parallelism and 4-way model parallelism is distributed across 8 GPUs: the model is partitioned across 4 GPUs, and each partition is added to 2 GPUs.
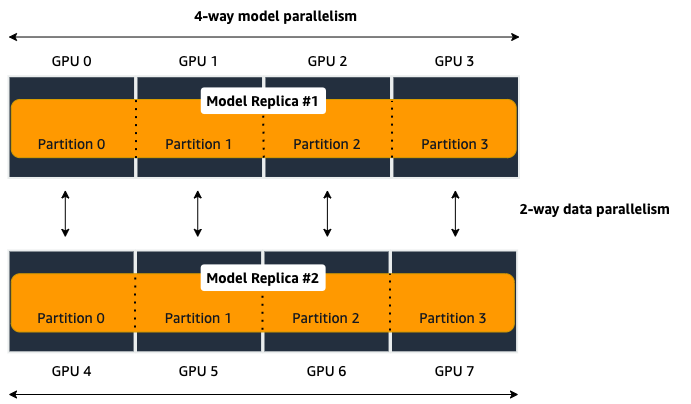
"custom_mpi_options": Use this key to pass any custom MPI options you might need. To avoid Docker warnings from contaminating your training logs, we recommend the following flag.`--mca btl_vader_single_copy_mechanism none`
Ranking Basics¶
The library maintains a one-to-one mapping between processes and available GPUs:
for each GPU, there is a corresponding CPU process. Each CPU process
maintains a “rank” assigned by MPI, which is a 0-based unique index for
the process. For instance, if a training job is launched with 4
p3dn.24xlarge instances using all its GPUs, there are 32 processes
across all instances, and the ranks of these processes range from 0 to
31.
The local_rank of a process is the rank of the process among the
processes in the same instance. This can range from 0 up to the number
of GPUs in the instance, but can be lower if fewer processes than GPUs are
launched in the instance. For instance, in the preceding
example, local_ranks of the processes will range from 0 to 7,
since there are 8 GPUs in a p3dn.24xlarge instance.
When the library is used together with data parallelism (Horovod for TensorFlow
and DDP for PyTorch), the library partitions the set of processes into
disjoint mp_groups. An mp_group is a subset of all processes
that together hold a single, partitioned model replica. For instance, if
a single node job is launched with 8 local processes, and
partitions is 2 (meaning the model will be split into 2), there are
four mp_groups. The specific sets of processes that form the
mp_groups can be adjusted by the placement_strategy option. In
this example, if placement_strategy is spread, then the four
mp_groups are [0, 4], [1, 5], [2, 6], [3, 7]. An
mp_rank is the rank of a process within its own mp_group. In the
previous example, the mp_rank of process 1 is 0, and mp_rank of
process 6 is 1.
Analogously, the library defines dp_groups as the sets of processes that
all hold the same model partition, and perform data parallelism among
each other. In the example above, there are two dp_groups,
[0, 1, 2, 3] and [4, 5, 6, 7],
since each process within the dp_group holds the same partition of
the model, and makes allreduce calls among themselves. Allreduce for
data parallelism does not take place across dp_groups.
dp_rank is defined as the rank of a process within its dp_group.
In the preceding example, the dp_rank of process 6 is 2.