Amazon SageMaker Processing¶
Amazon SageMaker Processing allows you to run steps for data pre- or post-processing, feature engineering, data validation, or model evaluation workloads on Amazon SageMaker.
Contents
Background¶
Amazon SageMaker lets developers and data scientists train and deploy machine learning models. With Amazon SageMaker Processing, you can run processing jobs on for data processing steps in your machine learning pipeline, which accept data from Amazon S3 as input, and put data into Amazon S3 as output.
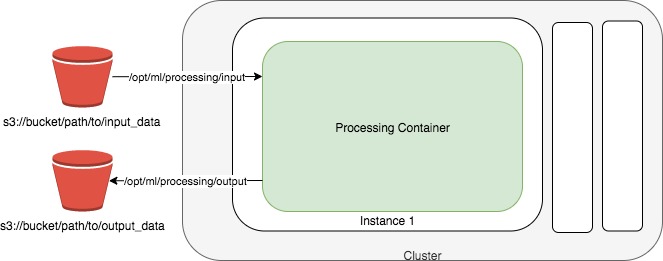
Setup¶
The fastest way to run get started with Amazon SageMaker Processing is by running a Jupyter notebook. You can follow the Getting Started with Amazon SageMaker guide to start running notebooks on Amazon SageMaker.
You can run notebooks on Amazon SageMaker that demonstrate end-to-end examples of using processing jobs to perform data pre-processing, feature engineering and model evaluation steps. See Learn More at the bottom of this page for more in-depth information.
Data Pre-Processing and Model Evaluation with Scikit-Learn¶
You can run a Scikit-Learn script to do data processing on SageMaker using the SKLearnProcessor class.
You first create a SKLearnProcessor
from sagemaker.sklearn.processing import SKLearnProcessor
sklearn_processor = SKLearnProcessor(framework_version='0.20.0',
role='[Your SageMaker-compatible IAM role]',
instance_type='ml.m5.xlarge',
instance_count=1)
Then you can run a Scikit-Learn script preprocessing.py in a processing job. In this example, our script takes one input from S3 and one command-line argument, processes the data, then splits the data into two datasets for output. When the job is finished, we can retrive the output from S3.
from sagemaker.processing import ProcessingInput, ProcessingOutput
sklearn_processor.run(code='preprocessing.py',
inputs=[ProcessingInput(
source='s3://your-bucket/path/to/your/data,
destination='/opt/ml/processing/input')],
outputs=[ProcessingOutput(output_name='train_data',
source='/opt/ml/processing/train'),
ProcessingOutput(output_name='test_data',
source='/opt/ml/processing/test')],
arguments=['--train-test-split-ratio', '0.2']
)
preprocessing_job_description = sklearn_processor.jobs[-1].describe()
For an in-depth look, please see the Scikit-Learn Data Processing and Model Evaluation example notebook.
Data Pre-Processing with Spark¶
You can use the ScriptProcessor class to run a script in a processing container, including your own container.
This example shows how you can run a processing job inside of a container that can run a Spark script called preprocess.py by invoking a command /opt/program/submit inside the container.
from sagemaker.processing import ScriptProcessor, ProcessingInput
spark_processor = ScriptProcessor(base_job_name='spark-preprocessor',
image_uri='<ECR repository URI to your Spark processing image>',
command=['/opt/program/submit'],
role=role,
instance_count=2,
instance_type='ml.r5.xlarge',
max_runtime_in_seconds=1200,
env={'mode': 'python'})
spark_processor.run(code='preprocess.py',
arguments=['s3_input_bucket', bucket,
's3_input_key_prefix', input_prefix,
's3_output_bucket', bucket,
's3_output_key_prefix', input_preprocessed_prefix],
logs=False)
For an in-depth look, please see the Feature Transformation with Spark example notebook.
Learn More¶
Processing class documentation¶
Processor: https://sagemaker.readthedocs.io/en/stable/processing.html#sagemaker.processing.ProcessorScriptProcessor: https://sagemaker.readthedocs.io/en/stable/processing.html#sagemaker.processing.ScriptProcessorSKLearnProcessor: https://sagemaker.readthedocs.io/en/stable/sagemaker.sklearn.html#sagemaker.sklearn.processing.SKLearnProcessorProcessingInput: https://sagemaker.readthedocs.io/en/stable/processing.html#sagemaker.processing.ProcessingInputProcessingOutput: https://sagemaker.readthedocs.io/en/stable/processing.html#sagemaker.processing.ProcessingOutputProcessingJob: https://sagemaker.readthedocs.io/en/stable/processing.html#sagemaker.processing.ProcessingJob
Further documentation¶
Processing class documentation: https://sagemaker.readthedocs.io/en/stable/processing.html
AWS Documentation: https://docs.aws.amazon.com/sagemaker/latest/dg/processing-job.html
AWS Notebook examples: https://github.com/awslabs/amazon-sagemaker-examples/tree/master/sagemaker_processing
Processing API documentation: https://docs.aws.amazon.com/sagemaker/latest/dg/API_CreateProcessingJob.html
Processing container specification: https://docs.aws.amazon.com/sagemaker/latest/dg/build-your-own-processing-container.html